
LLMs Don't Call Tools (And Why That Matters for Your Management Toolkit)
The surprising truth behind AI capabilities and how to use it to automate your biggest headaches

Here's a question that will blow your mind: What if I told you that ChatGPT has never actually called a single tool or function despite appearing to browse the web, analyze data, and interact with your files every day?
The truth behind how LLMs "use tools" is far stranger than most people realize. And understanding this illusion is the key to building better AI systems yourself.
Let's continue building your engineering management AI toolkit. As a reminder, we have two separate goals:
Learn about the fundamental technologies behind Large Language Models (LLMs). This is a transformational change that will change the course of tech for the coming decades. Building a deep understanding of how it works will help you understand its limitations, its quirks, and how to stay relevant for years to come
Scratch a real itch. We learn best when we learn on the job. By finding real leadership problems and building tools to help us, you will learn more, faster. And you will also gain immediate benefits in your day job. It's a double whammy.
To quickly recap, LLMs are auto-regressive models. They look at a blurb of text, and guess what the next word should be. This happens one word at a time, until the LLM chooses a special word, which means end-of-transmission.
(Even though the term 'token' is more accurate than 'word', I'll use the term 'word' for clarity in this post)
One of the surprising insights that you learned in the last post is that the LLM cannot distinguish which part of the 'blurb of text' is your original prompt, and which is part of its earlier reply.
In today's post you will learn more about what's happening behind the curtains—starting with that shocking revelation about tool calling.
To improve our employee simulator, you will make two key changes:
Use a thinking model
Add tool-calling capabilities
But first, let's upgrade our foundation.
Switching to a Smarter Model
Let's start where we left off, with a messy, hacky, single-file python script.
You are not building a production system. You are building tools that work just for you. This means that we will continue to take short-cuts. We'll skimp on error handling and edge cases in favor of shorter code.
Remember: our goal is to learn and to solve niche problems. 20% of the work will get us 80% of the benefit.
In the previous post, we used the Llama 3.2 model from Meta. Its main strength is its small model size, which makes it easy to run locally on your machine.
We're going to switch to a newer model with a similar size called qwen3. Why? Because this model will help us understand two critical concepts: thinking models and tool calling.
To install it, just run ollama run qwen3 in a terminal, and then just search and replace 'llama3.2' with 'qwen3' and run your python script (don't forget to activate your python virtual environment first).
When you run it, you'll see an immediate difference from llama. The model first "thinks out loud" and only then answers the query. You can turn this off by adding a '/nothink' string in your prompt.
This thinking behavior isn't just a quirk—it actually helps the model provide higher quality answers. By the end of this post, you should have stronger intuition for why.
But there's another reason we switched to this newer model, and it brings us to that mind-bending revelation I promised.
The Tool Calling Illusion
Both llama3.2 and qwen3 support tool calling. You can see this by the 'tools' tag on the respective model pages on ollama. Some other notable tags are 'vision' for models that can understand text and images, and 'thinking' for models that can 'think out loud'.
Qwen3 is a newer model that does a much better job than llama3.2 in using tools, and that's what we are going to explore now.
Calling tools to augment itself is one of the true super-powers that transform LLM from a curiosity to something that is truly useful.
The jump from a text-based autoregressive model to a robot with agency that can interact with the external world is, well, downright strange.
Most people don't really stop to think about it.
Here we had a piece of computer software that can only guess the next word, based on a blurb of text. And now we have something that can surf the web, interact with databases, and read your disk. And it's supposed to be, basically, the same thing?!
The problem is the abstractions. Abstractions are great for productivity, but they hide what's really happening.
And if we remove the curtain, it's clear that LLMs can still only guess the next word.
They can't call tools.
They really can't.
Here's what's actually happening behind the scenes—and why this matters for everything you build:
In the text blurb that you feed into the LLM, you include a list of functions. You include the function names, parameters, and a short description of what the function does.
When the LLM gets the text blurb, it still tries to guess the next word. The next word might be the name of a function.
If the last word was the name of a function, the next words will likely be the parameters to feed into the function.
After that, the most likely word will be the special end of transmission word.
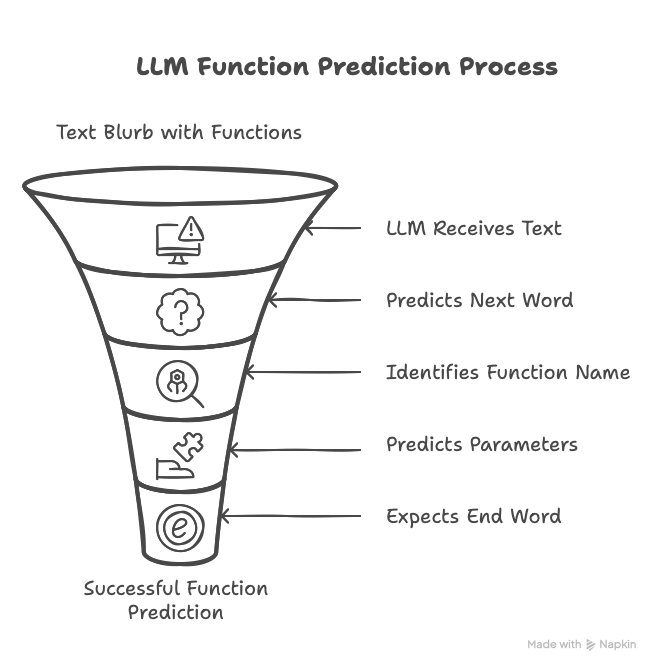
And that's it.
The LLM did not call the function.
All it did was spit out the name of a function and the parameters to feed into it. Now, this does require LLMs that were trained to do this, which is why many models on ollama do not have the 'tools' tag.
In a real life application, it is your job to parse the LLM's response, recognize that it wants to call a function, call that function, and then call the LLM again with the output of the function.
With this knowledge, you can write python scripts to help the LLM make you more effective in your job. For example, you can gather context from across your company’s systems to help you prepare for your upcoming 1:1s.
This understanding changes everything about how you think about AI systems. But there's more happening under the hood that platforms like ChatGPT abstract away from you.
The Template Secret
Let's dive deeper into what our platforms abstract away.
Every model has its own template. This template determines how conversations, tools, and system instructions get formatted into that single text blurb the LLM actually sees.
Here is qwen3's template:
{{- $lastUserIdx := -1 -}}
{{- range $idx, $msg := .Messages -}}
{{- if eq $msg.Role "user" }}{{ $lastUserIdx = $idx }}{{ end -}}
{{- end }}
{{- if or .System .Tools }}<|im_start|>system
{{ if .System }}
{{ .System }}
{{- end }}
{{- if .Tools }}
# Tools
You may call one or more functions to assist with the user query.
You are provided with function signatures within <tools></tools> XML tags:
<tools>
{{- range .Tools }}
{"type": "function", "function": {{ .Function }}}
{{- end }}
</tools>
For each function call, return a json object with function name and arguments within <tool_call></tool_call> XML tags:
<tool_call>
{"name": <function-name>, "arguments": <args-json-object>}
</tool_call>
{{- end -}}
<|im_end|>
{{ end }}
{{- range $i, $_ := .Messages }}
{{- $last := eq (len (slice $.Messages $i)) 1 -}}
{{- if eq .Role "user" }}<|im_start|>user
{{ .Content }}
{{- if and $.IsThinkSet (eq $i $lastUserIdx) }}
{{- if $.Think -}}
{{- " "}}/think
{{- else -}}
{{- " "}}/no_think
{{- end -}}
{{- end }}<|im_end|>
{{ else if eq .Role "assistant" }}<|im_start|>assistant
{{ if (and $.IsThinkSet (and .Thinking (or $last (gt $i $lastUserIdx)))) -}}
<think>{{ .Thinking }}</think>
{{ end -}}
{{ if .Content }}{{ .Content }}
{{- else if .ToolCalls }}<tool_call>
{{ range .ToolCalls }}{"name": "{{ .Function.Name }}", "arguments": {{ .Function.Arguments }}}
{{ end }}</tool_call>
{{- end }}{{ if not $last }}<|im_end|>
{{ end }}
{{- else if eq .Role "tool" }}<|im_start|>user
<tool_response>
{{ .Content }}
</tool_response><|im_end|>
{{ end }}
{{- if and (ne .Role "assistant") $last }}<|im_start|>assistant
{{ if and $.IsThinkSet (not $.Think) -}}
<think>
</think>
{{ end -}}
{{ end }}
{{- end }}
Remember: The LLM gets just one text blurb as input.
The entire conversation history? It becomes part of this single text prompt. The available tools? Part of the text prompt.
After the LLM returns the text asking for a tool, you call the tool, and then send another request to the LLM. And you keep the history of the LLM asking to call the tool, with your reply later on, in a structured format.
Every LLM has its own template format. Because all the LLM actually gets as input is one single large text blurb, you don't really have to comply with this template.
But you should. Because the LLM was trained with the template (typically in post-training). Even slight deviations can lead to drastic reduction in quality.
This leads us to an incredible challenge that reveals the true magic of modern LLMs.
The Context Window Challenge
Every model has a context window. Qwen3 has a context window of 128,000 tokens (the 4B and smaller variants have a smaller context window). And here I did use 'token' instead of 'word', because the distinction is important. A token can be a word, but is more commonly just a part of a word, or even just a punctuation sign. 128K tokens is roughly 35,000-42,000 English words.
For reference, this is enough to include all of George Orwell's Animal Farm, but not much more.
Now here's where things get truly mind-bending. Let's run through this thought experiment:
You call the LLM with a prompt and some available tools. Let's say you've done some back and forth and provided a lot of context. All of this is expanded using the model template into a single text blurb. Roughly the length of a short novella.
Near the start of the novella-long blurb, there is a list of tools that the LLM should call.
And near the end of the novella-long blurb, there is text that suggests calling these tools.
How does the LLM, which guesses one word at a time, make the connection? How can it correctly guess connections between words, with a literal novella standing in the middle?
It turns out that this is exactly at the heart of what makes modern LLMs so useful. Which we'll explore in the next post 🙂.
Key Takeaways
Here's what you learned today that most people don't understand about LLMs:
The Tool Calling Illusion: LLMs never actually call tools, they just output text that looks like function calls. Your application parses this text and calls the functions.
Templates Matter: Every model has a specific template that converts conversations into a single text blob. Deviating from these templates can drastically reduce quality.
I introduced two new insights which you will fully understand in the next post:
Context Window Magic: LLMs can somehow connect information separated by thousands of words in a single prompt. This ability is the fundamental breakthrough in large language models.
Thinking Models: Models that "think out loud" before answering provide higher quality responses.
Understanding these mechanics isn't just academic—it's practical. When you know how the magic trick works, you can build better prompts, design more effective AI workflows, and troubleshoot when things go wrong.
P.S. Did you get why thinking out loud works? Let's discuss in the comments 👇